 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Token Reduction via Rectifying Distortions for Efficient Multimodal LLM Inference
Jun 01, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have achieved remarkable success in vision-language tasks, yet the quadratic computational complexity arising from the vast number of visual tokens incurs significant memory and latency bottlenecks. While visual token reduction (VTR) strategies have been explored to mitigate this burden, existing methods overlook the positional and attentional consistency between the full and reduced sequences, resulting in a distorted representation. To this end, we propose RESTORE, a novel VTR framework that rectifies the positional and attentional distortions while maintaining efficiency. Specifically, we present a simple yet effective calibration method that restores lost visual attention by augmenting attention weights based on relative distances. We also introduce a distinctive anchor selection for token merging to mitigate information loss during feature averaging. Experimental results on multiple benchmarks demonstrate that our method consistently improves the accuracy of various reduction methods, achieving state-of-the-art performance while maintaining computational efficiency.
Hookpad Aria: A Copilot for Songwriters
Feb 12, 2025

We present Hookpad Aria, a generative AI system designed to assist musicians in writing Western pop songs. Our system is seamlessly integrated into Hookpad, a web-based editor designed for the composition of lead sheets: symbolic music scores that describe melody and harmony. Hookpad Aria has numerous generation capabilities designed to assist users in non-sequential composition workflows, including: (1) generating left-to-right continuations of existing material, (2) filling in missing spans in the middle of existing material, and (3) generating harmony from melody and vice versa. Hookpad Aria is also a scalable data flywheel for music co-creation -- since its release in March 2024, Aria has generated 318k suggestions for 3k users who have accepted 74k into their songs. More information about Hookpad Aria is available at https://www.hooktheory.com/hookpad/aria
SoundBrush: Sound as a Brush for Visual Scene Editing
Dec 31, 2024



We propose SoundBrush, a model that uses sound as a brush to edit and manipulate visual scenes. We extend the generative capabilities of the Latent Diffusion Model (LDM) to incorporate audio information for editing visual scenes. Inspired by existing image-editing works, we frame this task as a supervised learning problem and leverage various off-the-shelf models to construct a sound-paired visual scene dataset for training. This richly generated dataset enables SoundBrush to learn to map audio features into the textual space of the LDM, allowing for visual scene editing guided by diverse in-the-wild sound. Unlike existing methods, SoundBrush can accurately manipulate the overall scenery or even insert sounding objects to best match the audio inputs while preserving the original content. Furthermore, by integrating with novel view synthesis techniques, our framework can be extended to edit 3D scenes, facilitating sound-driven 3D scene manipulation. Demos are available at https://soundbrush.github.io/.
LLM-as-a-Judge & Reward Model: What They Can and Cannot Do
Sep 17, 2024LLM-as-a-Judge and reward models are widely used alternatives of multiple-choice questions or human annotators for large language model (LLM) evaluation. Their efficacy shines in evaluating long-form responses, serving a critical role as evaluators of leaderboards and as proxies to align LLMs via reinforcement learning. However, despite their popularity, their effectiveness outside of English remains largely unexplored. In this paper, we conduct a comprehensive analysis on automated evaluators, reporting key findings on their behavior in a non-English environment. First, we discover that English evaluation capabilities significantly influence language-specific capabilities, often more than the language proficiency itself, enabling evaluators trained in English to easily transfer their skills to other languages. Second, we identify critical shortcomings, where LLMs fail to detect and penalize errors, such as factual inaccuracies, cultural misrepresentations, and the presence of unwanted language. Finally, we release Kudge, the first non-English meta-evaluation dataset containing 5,012 human annotations in Korean.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024



In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams
Oct 16, 2023



Test-time adaptation (TTA) aims to address distributional shifts between training and testing data using only unlabeled test data streams for continual model adaptation. However, most TTA methods assume benign test streams, while test samples could be unexpectedly diverse in the wild. For instance, an unseen object or noise could appear in autonomous driving. This leads to a new threat to existing TTA algorithms; we found that prior TTA algorithms suffer from those noisy test samples as they blindly adapt to incoming samples. To address this problem, we present Screening-out Test-Time Adaptation (SoTTA), a novel TTA algorithm that is robust to noisy samples. The key enabler of SoTTA is two-fold: (i) input-wise robustness via high-confidence uniform-class sampling that effectively filters out the impact of noisy samples and (ii) parameter-wise robustness via entropy-sharpness minimization that improves the robustness of model parameters against large gradients from noisy samples. Our evaluation with standard TTA benchmarks with various noisy scenarios shows that our method outperforms state-of-the-art TTA methods under the presence of noisy samples and achieves comparable accuracy to those methods without noisy samples. The source code is available at https://github.com/taeckyung/SoTTA .
RPLKG: Robust Prompt Learning with Knowledge Graph
Apr 21, 2023



Large-scale pre-trained models have been known that they are transferable, and they generalize well on the unseen dataset. Recently, multimodal pre-trained models such as CLIP show significant performance improvement in diverse experiments. However, when the labeled dataset is limited, the generalization of a new dataset or domain is still challenging. To improve the generalization performance on few-shot learning, there have been diverse efforts, such as prompt learning and adapter. However, the current few-shot adaptation methods are not interpretable, and they require a high computation cost for adaptation. In this study, we propose a new method, robust prompt learning with knowledge graph (RPLKG). Based on the knowledge graph, we automatically design diverse interpretable and meaningful prompt sets. Our model obtains cached embeddings of prompt sets after one forwarding from a large pre-trained model. After that, model optimizes the prompt selection processes with GumbelSoftmax. In this way, our model is trained using relatively little memory and learning time. Also, RPLKG selects the optimal interpretable prompt automatically, depending on the dataset. In summary, RPLKG is i) interpretable, ii) requires small computation resources, and iii) easy to incorporate prior human knowledge. To validate the RPLKG, we provide comprehensive experimental results on few-shot learning, domain generalization and new class generalization setting. RPLKG shows a significant performance improvement compared to zero-shot learning and competitive performance against several prompt learning methods using much lower resources.
Towards Explainable AI Writing Assistants for Non-native English Speakers
Apr 05, 2023



We highlight the challenges faced by non-native speakers when using AI writing assistants to paraphrase text. Through an interview study with 15 non-native English speakers (NNESs) with varying levels of English proficiency, we observe that they face difficulties in assessing paraphrased texts generated by AI writing assistants, largely due to the lack of explanations accompanying the suggested paraphrases. Furthermore, we examine their strategies to assess AI-generated texts in the absence of such explanations. Drawing on the needs of NNESs identified in our interview, we propose four potential user interfaces to enhance the writing experience of NNESs using AI writing assistants. The proposed designs focus on incorporating explanations to better support NNESs in understanding and evaluating the AI-generated paraphrasing suggestions.
Robust Continual Test-time Adaptation: Instance-aware BN and Prediction-balanced Memory
Aug 10, 2022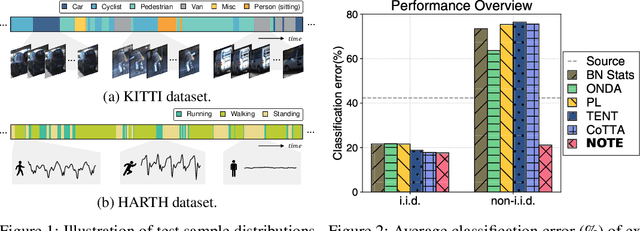
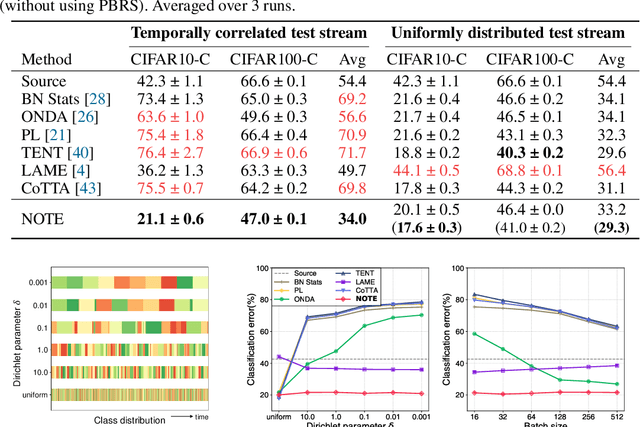
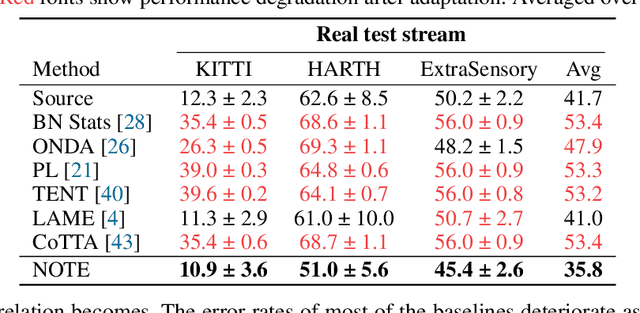
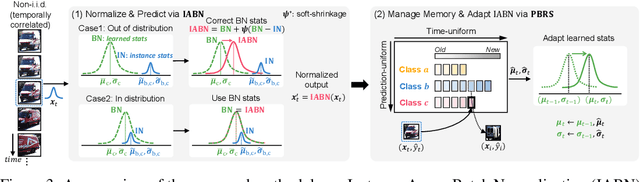
Test-time adaptation (TTA) is an emerging paradigm that addresses distributional shifts between training and testing phases without additional data acquisition or labeling cost; only unlabeled test data streams are used for continual model adaptation. Previous TTA schemes assume that the test samples are independent and identically distributed (i.i.d.), even though they are often temporally correlated (non-i.i.d.) in application scenarios, e.g., autonomous driving. We discover that most existing TTA methods fail dramatically under such scenarios. Motivated by this, we present a new test-time adaptation scheme that is robust against non-i.i.d. test data streams. Our novelty is mainly two-fold: (a) Instance-Aware Batch Normalization (IABN) that corrects normalization for out-of-distribution samples, and (b) Prediction-balanced Reservoir Sampling (PBRS) that simulates i.i.d. data stream from non-i.i.d. stream in a class-balanced manner. Our evaluation with various datasets, including real-world non-i.i.d. streams, demonstrates that the proposed robust TTA not only outperforms state-of-the-art TTA algorithms in the non-i.i.d. setting, but also achieves comparable performance to those algorithms under the i.i.d. assumption.
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022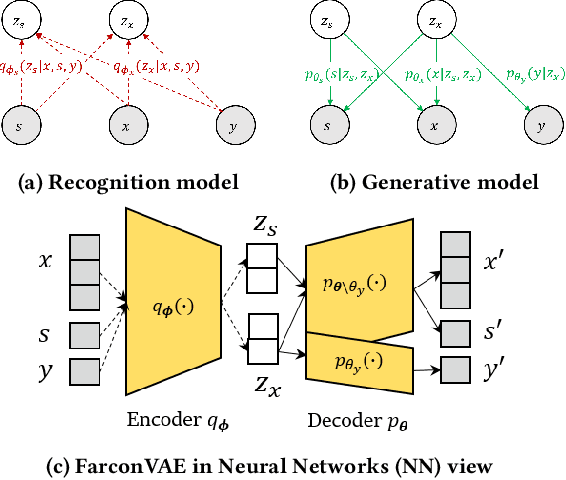
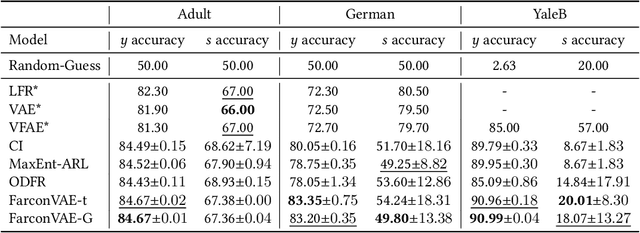
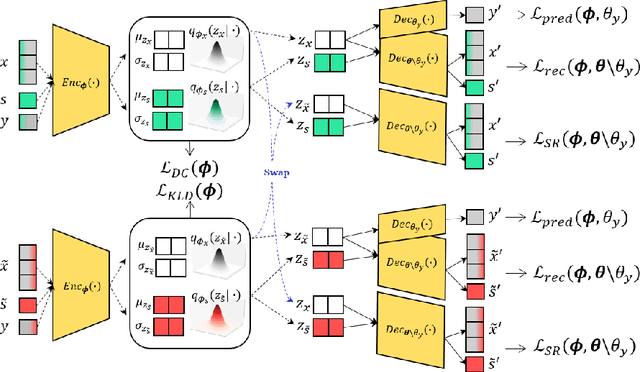
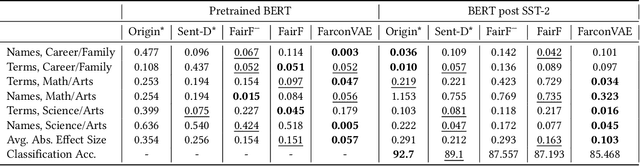
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.